RescueAuthKit
RescueAuthKit 是我写的一个 2FA Vault。写它的动机很现实:我之前一直在用 Microsoft Authenticator,但我的主力手机是鸿蒙系统,安装 Google 那套生态并不顺畅;而 Google Authenticator 和 Microsoft Authenticator 又都需要通过“出境易”这类环境去装,使用上总有点膈应。
更麻烦的是备份与迁移。在我的设备与网络环境里,Microsoft Authenticator 的备份经常不可用(也可能是网络问题),导致“换机/跨端”这件事变得不确定。于是我干脆把目标改成一条更可控的路径:手机与电脑之间围绕同一份加密 vault 文件完成导入导出,不依赖特定生态,也不需要猜“这个 App 到底支不支持某种迁移格式”。
这也是一次 Flutter 的学习项目:正好自己有需求,就用最小可用的方式把它做出来,并持续迭代。
另外,我过去一直没有找到一个顺手的地方保存恢复码(recovery codes),所以把它也作为一等公民放进 vault 里,和 TOTP 一起迁移与备份。
至于密码管理(password manager)我没有做:一方面确实没有刚需,Edge 浏览器的密码管理与同步已经足够;另一方面我不想把范围扩大成另一个复杂产品。
平台支持方面,目前我主要覆盖 Windows + Android。因为我没有 macOS 设备,iOS / macOS 暂时没法做成“开箱即用”的分发形式;有需要的话只能自行拉代码编译运行。
这个项目是我自己日常在用的工具,所以会长期更新;质量标准也会以“自己敢用”为底线。
GitHub: xincy22/rescue_auth_kit
代码结构(按职责)
lib/
main.dart # 启动入口
app.dart # Provider 注入 + RootGate 路由
core/
crypto/vault_crypto.dart # vault 文件协议 + KDF + AEAD
vault/vault_models.dart # VaultData / TotpEntry / RecoveryCodeSet
vault/vault_repository.dart # 文件 IO + 导入导出 + 原子写
vault/vault_session.dart # 会话状态机(对上层暴露的唯一入口)
import/otpauth_parser.dart # 导入边界(URI 解析 + secret 标准化 + 参数校验)
features/
auth/create_vault_screen.dart
auth/unlock_screen.dart
home/home_shell.dart
totp/totp_screen.dart
recovery/recovery_screens.dart
backup/backup_screen.dart
scan/scan_screen.dart
scan/paste_uri_dialog.dart
scan/confirm_import_screen.dart
l10n/ # 中英文本地化(本文略过细节)第一部分:Vault 文件层(协议 + 文件 IO)
这一部分是项目最内核的边界:把一份内存里的 VaultData 变成一个可以复制、可以迁移、可以恢复的文件。
为了把边界压实,我把这一层拆成两块:
vault_crypto.dart定义“文件长什么样”和“怎么加解密”。vault_repository.dart定义“怎么读写文件”和“怎么避免写坏/误覆盖”。
这一层的输入输出也很清晰:
- 输入:主密码(只在解锁/导入时出现一次)或 vault bytes
- 输出:
VaultHandle(包含解密后的数据 + 加密所需的上下文)或 vault bytes
1) vault_crypto.dart:把 vault 文件协议钉死
我希望迁移文件至少具备三个性质:可识别、可演进、载荷全加密。
因此 vault 文件采用 JSON envelope(头部元数据明文,payload 全密文)。核心字段是:
magic:识别文件归属version:协议版本kdf:KDF 参数与 salt(写入文件,保证历史文件可解锁)cipher:加密算法标识nonce/mac/ciphertext:AEAD 结果(base64url 存储)
对应的数据结构是 VaultFile:
class VaultFile {
final int version;
final VaultKdfParams kdf;
final String cipher;
final Uint8List nonce;
final Uint8List mac;
final Uint8List ciphertext;
}KDF 采用 Argon2id,参数被封装进 VaultKdfParams 并写入文件。这样做的关键收益是:
- 默认参数可以升级,但旧文件不需要依赖“当前默认值”
- 解析文件即可知道“当时用的是什么派生参数”,协议可追溯
final kdf = Argon2id(
memory: params.memoryKiB,
iterations: params.iterations,
parallelism: params.parallelism,
hashLength: params.hashLengthBytes,
);
return kdf.deriveKeyFromPassword(password: password, nonce: params.salt);加密则用 AEAD(XChaCha20-Poly1305),把 SecretBox 的三元组映射回 VaultFile:
final box = await cipher.encrypt(cleartextJsonBytes, secretKey: key);
return VaultFile(
version: rescueAuthKitVaultVersion,
kdf: kdfParams,
cipher: rescueAuthKitCipherXchacha20Poly1305,
nonce: Uint8List.fromList(box.nonce),
mac: Uint8List.fromList(box.mac.bytes),
ciphertext: Uint8List.fromList(box.cipherText),
);这里的约束非常强:如果 mac 不匹配,解密就会抛 SecretBoxAuthenticationError。这一点后面会被仓库层拿来做“错密码/文件损坏”的判定。
2) vault_repository.dart:把“文件 IO”做成可预测的流程
VaultRepository 是“加密协议”和“上层状态机”之间的那道墙:
- 负责默认路径、读写、导入导出
- 负责把底层错误归类成明确异常
- 负责写盘策略(尽量不写坏、不误覆盖)
2.1 错误模型:三类异常足够表达问题
我没有把底层异常直接往上抛,而是在仓库层做了一次归类:
VaultIoException:文件不存在、无法读写等 IO 问题VaultFormatException:不是本项目 vault、字段缺失、cipher 不支持、payload 非法VaultAuthException:认证失败(典型是错密码,或密文/mac被篡改)
这样上层只需要关心“是哪一类问题”,而不是去理解密码学/文件系统的细枝末节。
2.2 为什么返回 VaultHandle,而不是只返回 VaultData
仓库打开/创建后返回 VaultHandle:
data:解密后的VaultDatakey:派生出的SecretKeykdfParams:文件内 KDF 参数cipher:算法标识
这不是为了“多封一层”,而是为了把性能与边界一次性处理好:
- 解锁只发生一次;保存会发生很多次
- 我不想让每次保存都重新派生 key
- 我也不想在内存里保留明文主密码
VaultHandle 是一个很实用的折中:把“后续加密所需上下文”保留下来,但不保存密码。
2.3 创建新 vault:一次接收密码,立刻落盘
创建流程在仓库层闭合:
- 生成 salt,构造默认 KDF 参数
- 派生
SecretKey VaultData.empty()_writeEncrypted(...):序列化 -> 加密 ->_atomicWrite- 返回
VaultHandle
final data = VaultData.empty();
await _writeEncrypted(data: data, key: key, kdfParams: kdfParams);
return VaultHandle(
data: data,
key: key,
kdfParams: kdfParams,
cipher: rescueAuthKitCipherXchacha20Poly1305,
);2.4 打开 vault:校验顺序决定了错误可解释性
我刻意把打开顺序写成“先结构、再算法、再派生、再解密、最后解析 payload”。
- 先检查文件存在(不存在就是 IO)
- 再
VaultFile.decode(...)(magic/version不对就是格式) - 再校验
cipher(不支持就是格式) - 再派生 key(参数来自文件内
kdf) - 再解密(认证失败就是
VaultAuthException) - 最后解析 payload(解析失败就是格式)
这样一来,上层拿到异常就能比较准确地知道“问题在哪一层”。
2.5 导入/导出:先验证再覆盖,避免把本地 vault 写没
导出 exportBytes() 的语义很单纯:读当前 vault 文件 bytes。
导入 importBytes(bytes, password) 的关键在顺序:先解密验证成功,再覆盖本地文件。
final vaultFile = VaultFile.decode(bytes);
final key = await crypto.deriveKeyFromPassword(
password: password,
params: vaultFile.kdf,
);
final clearBytes = await crypto.decryptFile(file: vaultFile, key: key);
final obj = jsonDecode(utf8.decode(clearBytes)) as Map<String, dynamic>;
final data = VaultData.fromJson(obj);
await _atomicWrite(bytes);这条顺序的意义非常明确:
- 错密码不会覆盖本地文件
- 坏文件不会覆盖本地文件
- 只有“协议可解析 + 密钥认证通过 + payload 可解析”才允许落盘
2.6 _atomicWrite:跨平台语义下的“足够好”
严格的原子写依赖文件系统语义,跨平台很难完全统一。
这里我采用的是一种“足够好”的写盘策略:
- 写
vault.tmp(flush: true) - 旧文件 rename 为
.bak;rename 失败则退化为复制.bak+ 删除旧文件 tmprename 为正式文件- 删除
.bak
await tmp.writeAsBytes(bytes, flush: true);
if (await file.exists()) {
try {
await file.rename(bak.path);
} catch (_) {
await bak.writeAsBytes(await file.readAsBytes(), flush: true);
await file.delete();
}
}
await tmp.rename(file.path);
if (await bak.exists()) await bak.delete();它不保证所有场景的“严格原子”,但能显著降低写入中断造成的半文件风险;并且引入 .bak 作为最后的回退缓冲。
3) 这一层我用什么测试把它锁住
这部分最应该被测试锁死的,是“可逆性”和“不会误覆盖”。对应测试文件:
test/core/crypto/vault_crypto_test.dart- 加密 -> 编码 -> 解码 -> 解密闭环
- 错密码必须认证失败
test/core/vault/vault_repository_test.dartcreateNewVault -> open可用save的变更可持久化exportBytes/importBytes的跨仓库 roundtrip
第二部分:会话层(vault_session.dart)
Vault 文件层解决了“怎么把数据可靠落盘”。但在实际应用里,上层并不应该直接调用 repository 或 crypto;否则 UI 很快会演变成“到处写盘、到处 try/catch”。
VaultSession 的定位是:把 vault 的生命周期和写入口收口成一个可观察对象,上层只跟它交互。
1) 会话状态:locked/unlocked + 强制解锁语义
会话状态由两部分组成:
_status:对外可读的状态(locked/unlocked)_handle:真正的“能力凭证”(包含VaultData + SecretKey + KDF params)
读数据时,data getter 选择强制语义:锁定状态直接抛异常,而不是返回空值。
VaultData get data {
final h = _handle;
if (h == null) throw const VaultLockedException();
return h.data;
}这样上层必须先完成解锁流程,避免 UI 里出现大量“软判断”分支。
2) 对上层暴露了哪些 API
对 UI 来说,VaultSession 提供两类能力:生命周期与数据写入口。
- 生命周期:
vaultExists():用于决定“创建还是解锁”的入口分流createNew(password):创建新 vault 并进入unlockedunlock(password):打开现有 vault 并进入unlockedimportVault(vaultBytes, password):导入 vault 并进入unlockedlock():清空 handle,回到locked
- 读状态:
status、isUnlockeddata(锁定会抛VaultLockedException)
- 写入口:
addTotpFromParsed(parsed):追加一条 TOTP(内部生成 UUID 与createdAt)addRecoverySet(title, codes):追加一组 recovery codes(内部做trim/过滤空行)removeRecoverySet(id):删除一组 recovery codessetData(newData)+save():低层逃生口,用于批量编辑或组合操作
这里有个刻意的区分:
add*/remove*会在一次用户动作内完成持久化(内部直接repo.save)。setData只改内存并notifyListeners(),不自动落盘;由调用方显式save()控制落盘时机。
3) 写操作的固定管线:改内存 -> 落盘 -> 通知
为了避免“改了内存但忘记保存”这类分散错误,VaultSession 的高层写入口遵循一条固定管线:
final h = _handle ?? (throw const VaultLockedException());
final updated = h.data.copyWith(...);
_handle = h.copyWith(data: updated);
await _repo.save(_handle!);
notifyListeners();这条管线有两个直接收益:
- 一次操作对应一次落盘,失败路径清晰。
- UI 只监听 session 就能得到一致刷新,不需要关心保存时机。
4) 为什么 session 里要做 ID 生成与最小数据清洗
VaultSession 内部持有 Uuid,并在写入口做最小的数据规范化(例如 codes 的 trim 和空行过滤)。
原因是分层责任:
- repository 只负责“安全落盘”,不承担业务语义。
- models 只负责数据结构与序列化,尽量保持纯净。
- session 更贴近业务入口,适合承担“把输入变成可入库数据”的最后一步。
5) 测试如何验证 session 语义
test/core/vault/vault_session_test.dart 覆盖了三条关键语义:
createNew -> lock -> unlock的状态切换稳定- 错密码解锁会抛
VaultAuthException(由 repository 层上抛) setData + save的修改能在重新解锁后被读到(持久化语义正确)
第三部分:数据模型层(vault_models.dart)
vault_models.dart 是数据平面与序列化边界的定义处。我的目标不是做一个“很聪明”的模型层,而是做一个“足够稳定”的模型层:
- 字段明确:能够支撑 TOTP 生成与 recovery codes 管理的最小集合。
- 序列化稳定:文件格式长期可读,缺字段可回退,有问题能明确失败。
- 不可变倾向:尽量减少上层误改共享数据的机会。
1) schemaVersion:把兼容性变成显式字段
VaultData 持有 schemaVersion,当前常量为 1。它的意义是:当数据结构需要演进时,迁移逻辑有明确的分支入口,而不是靠“猜字段有没有”。
当前实现里 VaultData.fromJson 对缺失 schemaVersion 做了回退(默认 1),这能提升导入的韧性,也便于后续向前兼容。
const int vaultDataSchemaVersion = 1;
class VaultData {
final int schemaVersion;
// ...
}2) TOTP 参数建模:算法名的显式映射
TotpHashAlgorithm 只允许 sha1/sha256/sha512 三种;extension 提供 otpauth 协议中的字符串映射,并在遇到未知算法时明确抛 FormatException。
这相当于把“可接受的输入域”写进了模型层,而不是散落在导入解析或 UI 中。
enum TotpHashAlgorithm { sha1, sha256, sha512 }
extension TotpHashAlgorithmX on TotpHashAlgorithm {
String get otpauthName => switch (this) {
TotpHashAlgorithm.sha1 => 'SHA1',
TotpHashAlgorithm.sha256 => 'SHA256',
TotpHashAlgorithm.sha512 => 'SHA512',
};
}3) TotpEntry:最小但完备的持久化单元
TotpEntry 保存一条 TOTP 所需的全部信息:secretBase32、algorithm、digits、period,以及展示与可追溯字段(issuer/accountName/createdAt)。
反序列化时我区分了“必须字段”和“可回退字段”:
- 必须字段:
id、secretBase32、createdAt - 可回退字段:
issuer/accountName默认为空,algorithm/digits/period有默认值(SHA1/6/30)
这样做能避免“旧文件少字段就完全读不出来”,同时又能保证一条 entry 至少具备生成 TOTP 的必要数据。
factory TotpEntry.fromJson(Map<String, dynamic> json) {
final id = json['id'] as String?;
final secretBase32 = json['secretBase32'] as String?;
final createdAtStr = json['createdAt'] as String?;
if (id == null || secretBase32 == null || createdAtStr == null) {
throw FormatException('Invalid TOTP entry');
}
// ...
}4) RecoveryCodeSet:尽量不让格式噪声阻断导入
RecoveryCodeSet 的反序列化策略更偏“宽容”:只强制要求 id/createdAt,codes 如果不是列表则按空列表处理。
原因很简单:recovery code 的价值在于“能否被拿出来用”,而不是“历史上每一次写入都严格遵循类型”。在导入路径上,宽容往往比严格更接近用户预期。
5) VaultData:不可变倾向 + 可控的批量更新
VaultData 通过 copyWith 支持批量变更,但内部用 List.unmodifiable 把列表冻结,避免上层拿到引用后原地修改。
这会让写路径更健康:所有更新都必须显式走 copyWith,从而更容易与 session 的“改内存 -> 落盘”管线对齐。
VaultData copyWith({
List<TotpEntry>? totpEntries,
List<RecoveryCodeSet>? recoveryCodeSets,
}) {
return VaultData(
schemaVersion: schemaVersion,
totpEntries: List.unmodifiable(totpEntries ?? this.totpEntries),
recoveryCodeSets: List.unmodifiable(
recoveryCodeSets ?? this.recoveryCodeSets,
),
);
}VaultData.fromJson 对列表的解析也做了“类型过滤 + 显式拷贝”,把不符合预期的元素排除掉,再由子模型做更严格的字段校验。
6) 测试:把“格式稳定性”当作约束
test/core/vault/vault_models_test.dart 做的是最关键的那类测试:toJson/fromJson 的 roundtrip。
它验证了两个不变量:
- 写入的字段能被完整读回(包括时间字段)。
TotpEntry与RecoveryCodeSet的字段语义不会在重构中被不小心改掉。
第四部分:导入边界(otpauth_parser.dart)
otpauth_parser.dart 是导入路径的输入收敛层。它的职责很窄:把 URI 字符串解析成可入库对象 ParsedTotp,并在不满足约束时明确失败。它不涉及持久化,也不承载交互语义。
1) 输出模型:ParsedTotp
这个文件的输出结构刻意保持“最小但完备”:
- 能直接构造
TotpEntry(issuer/account/secret/algorithm/digits/period)。 - 不携带任何 UI 需要的状态(例如 loading/error 展示策略),上层自由决定如何呈现。
class ParsedTotp {
final String issuer;
final String accountName;
final String secretBase32;
final TotpHashAlgorithm algorithm;
final int digits;
final int period;
}2) secret 规范化:normalizeBase32Secret
导入的 secret 可能来自不同来源(二维码、复制粘贴、手工整理),常见问题是:夹杂空白/连字符、大小写混用、padding 不完整。
这个函数把 secret 收敛成 canonical 形式:
- 去空白与连字符
- 转大写
- 去掉已有
= - 按 8 的倍数补齐 padding
var s = raw.trim().replaceAll(RegExp(r'[\\s-]'), '').toUpperCase();
s = s.replaceAll('=', '');
final pad = (8 - (s.length % 8)) % 8;
return s + '=' * pad;这样做的结果是:同一个 secret 以不同表述输入时,会落到同一份稳定表示,后续的 TOTP 生成不会被“格式噪声”影响。
3) URI 解析:parseOtpauthTotpUri
解析流程按“先拒绝、再结构、再字段、再范围”的顺序展开,以保证失败语义清晰:
- 显式拒绝
otpauth-migration://(当前实现不支持该协议)。 Uri.parse,解析失败即报 “Invalid URI format”。- 校验协议:必须是
otpauth://totp/...。 secret必须存在且非空,然后做规范化。- 解析 label:支持
issuer:account,并允许 query 参数issuer覆盖 label 的 issuer。 - 解析
algorithm/digits/period并做范围校验。
关键的结构与范围约束(节选):
if (uri.scheme.toLowerCase() != 'otpauth' || uri.host.toLowerCase() != 'totp') {
throw const OtpAuthParseException('Not a valid otpauth TOTP URI.');
}
final secretRaw = uri.queryParameters['secret'];
if (secretRaw == null || secretRaw.trim().isEmpty) {
throw const OtpAuthParseException('Missing secret parameter.');
}
final algorithmStr = (uri.queryParameters['algorithm'] ?? 'SHA1').trim();
final algorithm = TotpHashAlgorithmX.fromOtpauthName(algorithmStr);
final digits = int.tryParse(uri.queryParameters['digits'] ?? '') ?? 6;
final period = int.tryParse(uri.queryParameters['period'] ?? '') ?? 30;
if (digits < 6 || digits > 10) {
throw const OtpAuthParseException('Digits not in valid range (6-10).');
}
if (period <= 0 || period > 120) {
throw const OtpAuthParseException('Period not in valid range (1-120).');
}issuer/account 的归一策略也写在解析边界里(节选):
final label = Uri.decodeComponent(uri.path).replaceFirst('/', '');
String issuerFromLabel = '';
String accountName = label;
if (label.contains(':')) {
final parts = label.split(':');
issuerFromLabel = parts.first.trim();
accountName = parts.sublist(1).join(':').trim();
}
final issuer = (uri.queryParameters['issuer'] ?? issuerFromLabel).trim();4) 错误语义:预期失败与非预期失败
这个文件把“常见、可解释”的失败统一表达为 OtpAuthParseException(message)(例如缺 secret、协议不匹配、范围不合法、migration 协议等)。
对于“不可接受的输入域”(例如不支持的 algorithm),会由 TotpHashAlgorithmX.fromOtpauthName 抛出 FormatException。上层可以把它视为“解析失败”的一类,但不应该将其与 vault 解密失败(VaultAuthException)混淆。
5) 测试:把解析行为钉成样例
test/features/scan/otpauth_parser_test.dart 覆盖了一个典型 otpauth://totp/... URI 的解析用例(issuer/account/digits/period)。
这类测试更像规格样例:它不追求穷尽输入,而是确保“常见输入路径”在重构中不会被误伤。
第五部分:UI 总览(app.dart + features/*)
UI 层的目标不是承载业务逻辑,而是把“状态机 + 写入口(VaultSession)”用一个可理解的页面结构呈现出来。我的约束是:UI 不直接碰 repository/crypto,所有数据读写都通过 session 完成。
1) 入口与门禁:main.dart / app.dart
main.dart只做三件事:初始化绑定、创建VaultRepository、启动RescueAuthKitApp。app.dart做依赖注入(VaultRepository+VaultSession),并用RootGate决定进入“创建 / 解锁 / 主界面”。
if (session.isUnlocked) {
return const HomeShell();
}
return FutureBuilder<bool>(
future: repo.vaultFileExists(),
builder: (context, snapshot) {
if (!snapshot.hasData) return const _Splash();
return snapshot.data! ? const UnlockScreen() : const CreateVaultScreen();
},
);这段门禁逻辑的好处是:上层不需要到处判断“有没有 vault / 是否解锁”,入口只有一个。
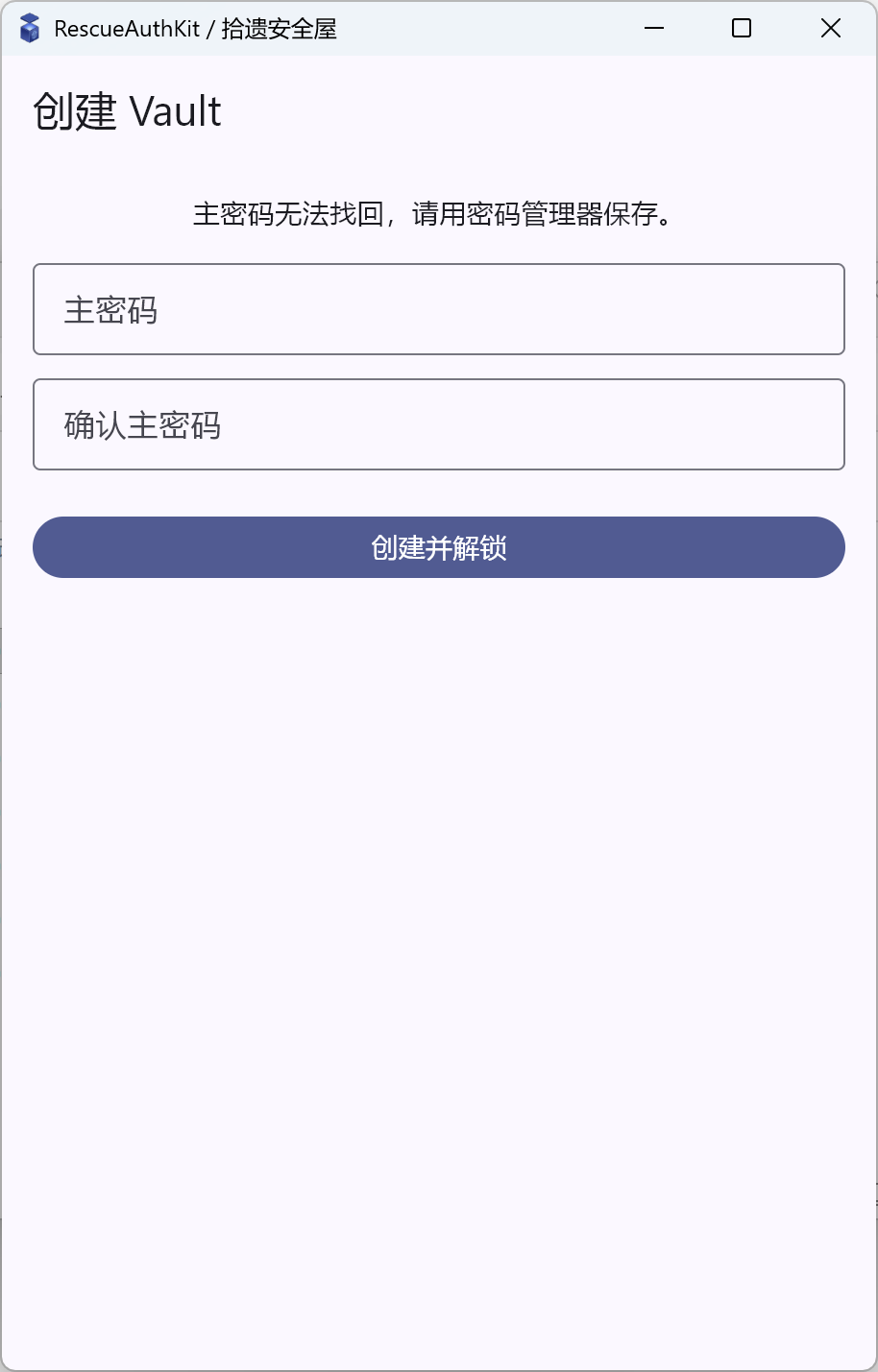
2) 解锁前两条路径:create_vault_screen.dart / unlock_screen.dart
CreateVaultScreen:双输入校验主密码(长度、两次一致),调用session.createNew(password),成功后 session 进入unlocked。UnlockScreen:输入主密码后调用session.unlock(password);错密码会被 repository 映射为VaultAuthException,UI 可明确给出“密码错误”提示。
这两页的共同点是:不处理加密细节,不处理文件路径,只负责把“用户输入”交给 session。
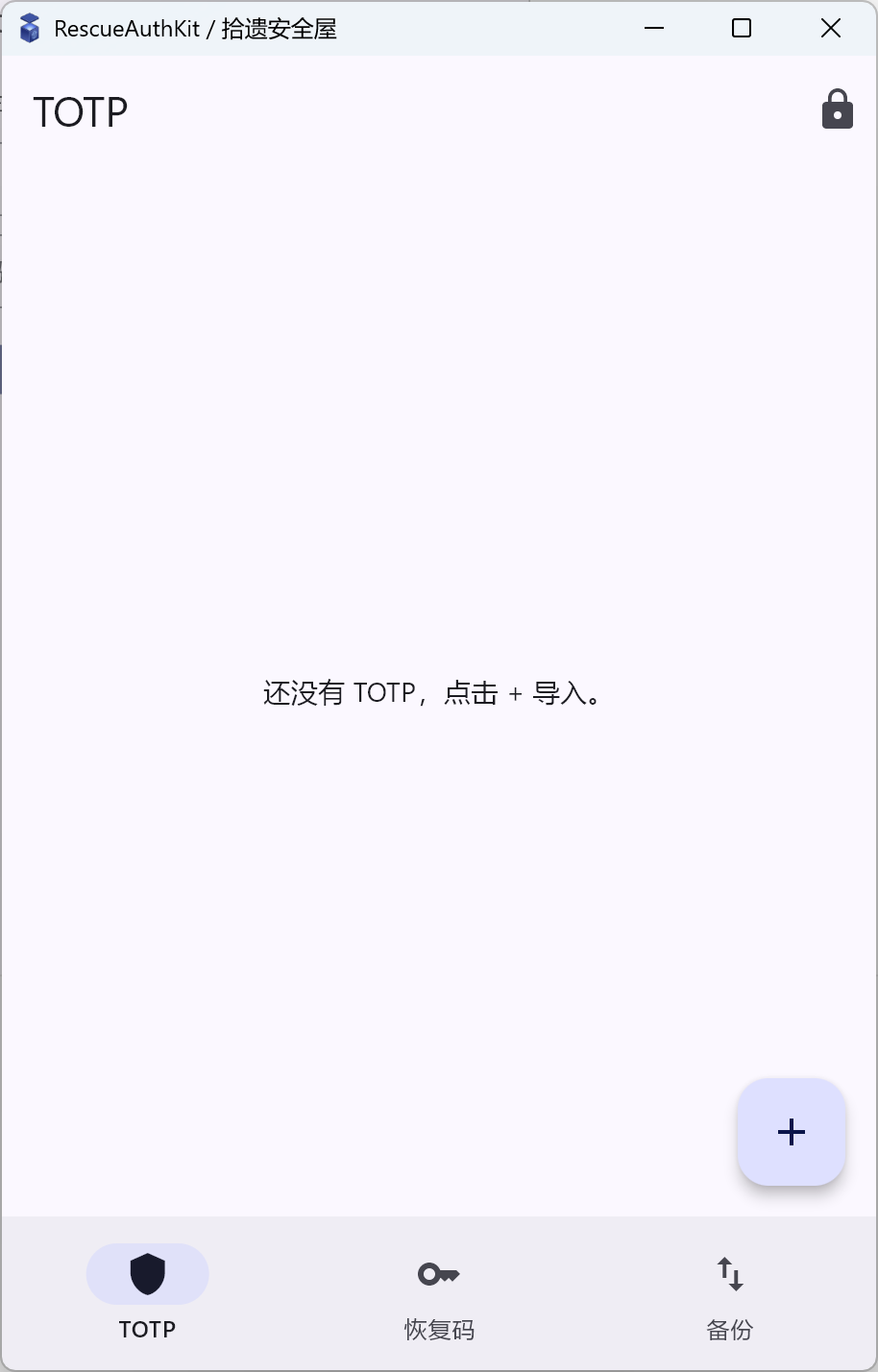
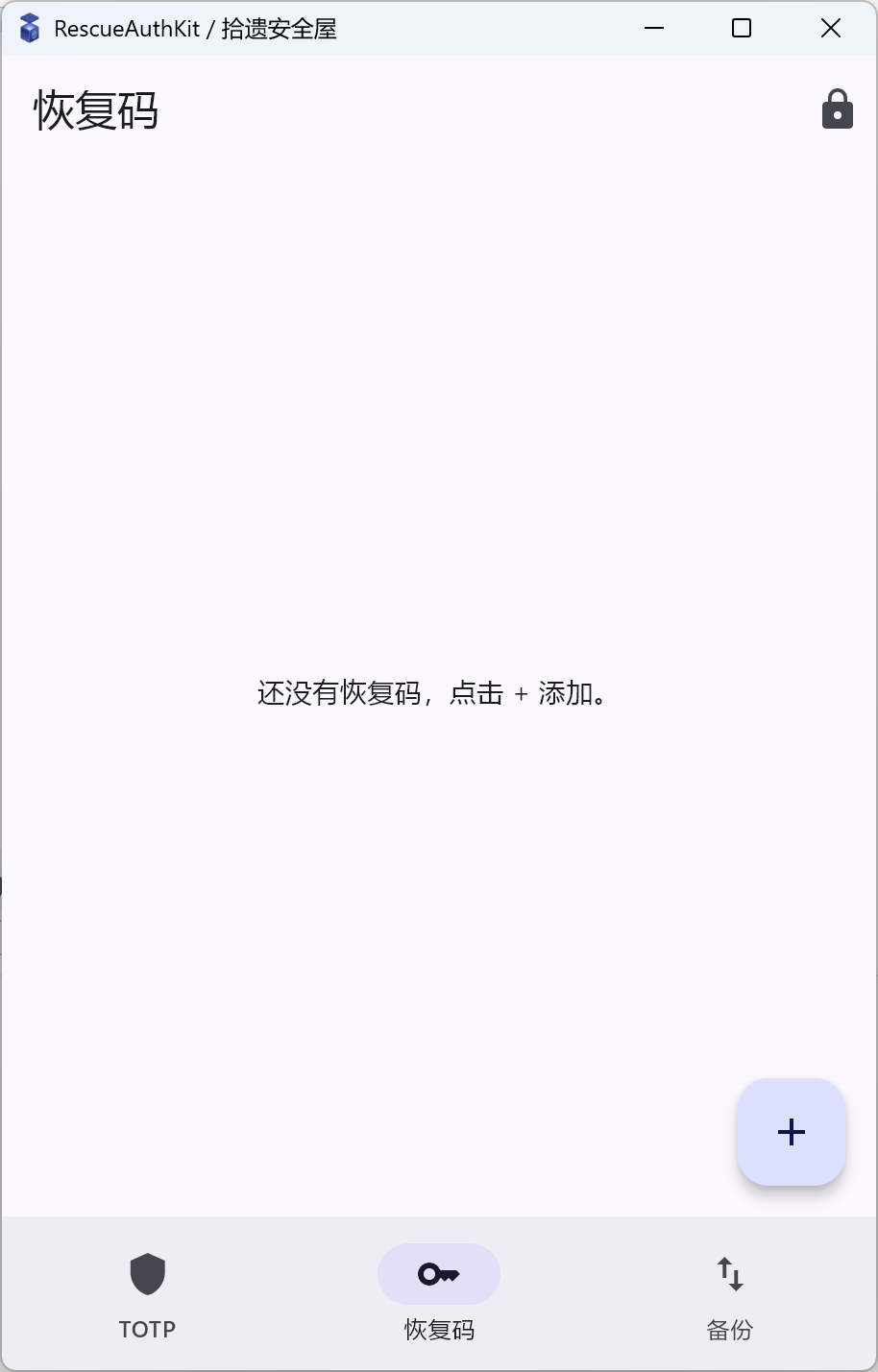
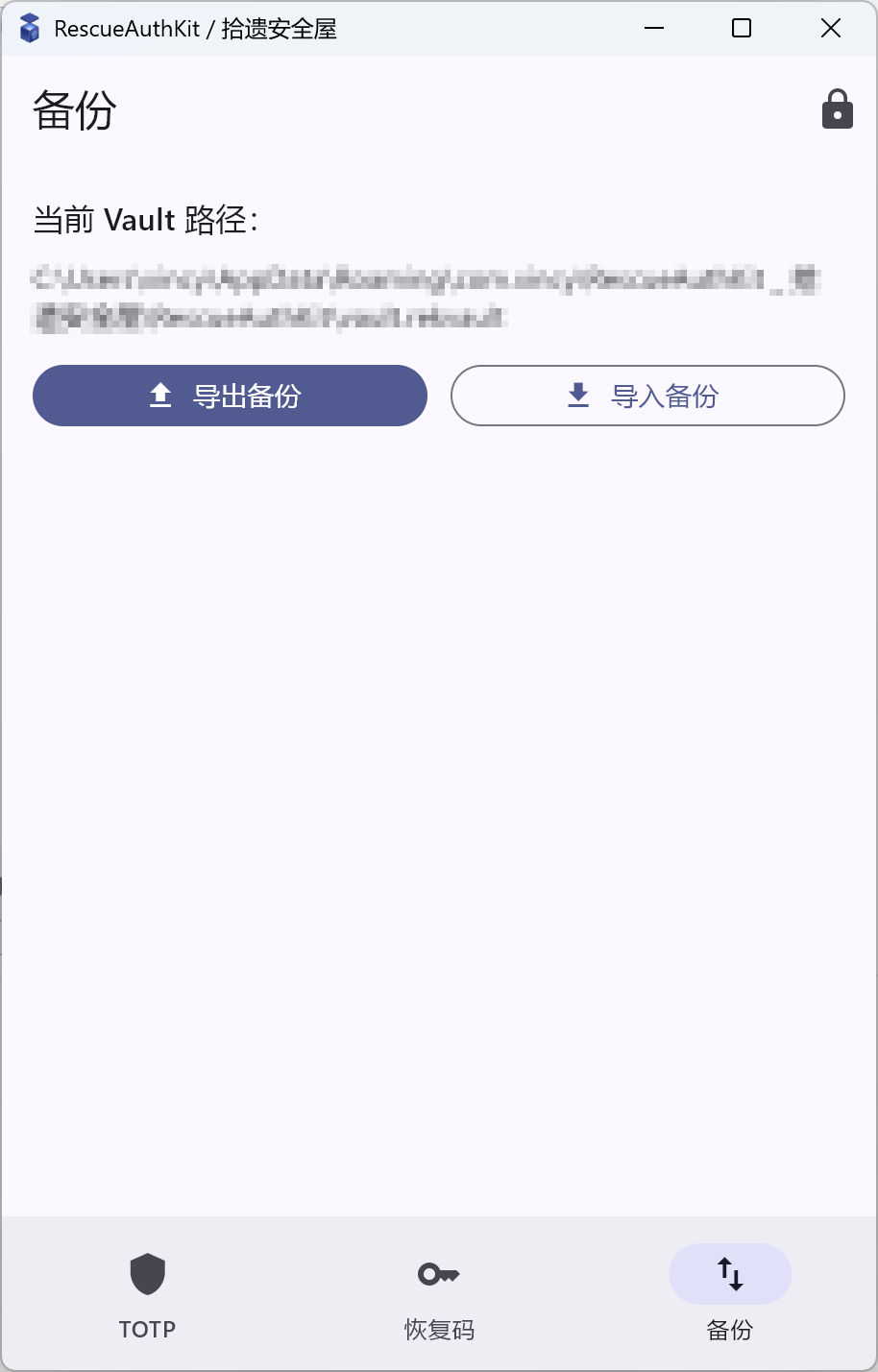
3) 解锁后的主壳:home_shell.dart
主界面用一个壳层承载三类任务,并保持 tab 状态不丢失:
- TOTP(查看与新增)
- Recovery codes(查看、新增、删除)
- Backup(导出/导入 vault 文件)
final pages = const [TotpScreen(), RecoveryScreen(), BackupScreen()];
return Scaffold(
body: IndexedStack(index: _index, children: pages),
bottomNavigationBar: NavigationBar(
selectedIndex: _index,
onDestinationSelected: (index) => setState(() => _index = index),
destinations: [...],
),
);此外在 AppBar 放了一个显式 lock(),把“锁定”变成随时可用的一键操作,避免用户只能通过系统后台切换来达成“锁定”。
4) 新增 TOTP 的导入流:scan_screen.dart / paste_uri_dialog.dart / confirm_import_screen.dart
新增 TOTP 的入口在 HomeShell 的 FAB,通过底部弹窗选择导入方式:
- Android:支持扫码与粘贴
- 桌面:只保留粘贴(
ScanScreen依赖手机摄像头场景)
流程是“拿到 raw URI -> 解析预览 -> 二次确认 -> 入库保存”:
ScanScreen使用mobile_scanner读取二维码 raw 值(并用_handled防止重复触发)。paste_uri_dialog.dart提供粘贴对话框,拿到otpauth://...文本。ConfirmImportScreen调parseOtpauthTotpUri解析,并允许用户调整issuer/account。- 点击保存时调用
session.addTotpFromParsed(...),由 session 负责生成 UUID、写盘与通知 UI。
这一套链路的关键是:解析失败在确认页就能被解释清楚,解析成功也会让用户看到“将要入库的字段”,避免静默写入错误标签。
5) 备份导入导出:backup_screen.dart
备份页展示当前 vault 文件路径,并提供导出/导入两条操作:
- 导出:读取
repo.exportBytes(),按平台把 bytes 交给系统能力- Android:写入临时文件后
share_plus分享 - Desktop:
file_selector选择保存位置
- Android:写入临时文件后
- 导入:
openFile选择 vault 文件 -> 二次确认覆盖 -> 输入主密码 ->session.importVault(...)
导入动作上我更强调“验证前不覆盖”:仓库层会先解密校验成功再写盘,上层只需处理“错密码 / 导入失败”的提示。
6) 展示与复制:totp_screen.dart / recovery_screens.dart
TotpScreen:定时刷新倒计时与验证码,支持一键复制;验证码生成使用otp库,算法映射由模型层控制。RecoveryScreen:以“set”为单位管理 recovery codes,支持查看、逐条复制、全部复制、删除与新增。
这两个页面都遵循同一原则:展示逻辑在 UI,数据来源与持久化都交给 session。
截图
到这里,核心实现与 UI 编排就完整了。